
In IT, observability has become the go-to strategy for managing the complexity of users, apps, and distributed systems. According to Cloud Data Insights, 90% of IT professionals say observability is not only important but strategic to their business.
And for good reason: observability provides visibility, event tracing, and context—essential for finding root causes and resolving issues quickly.
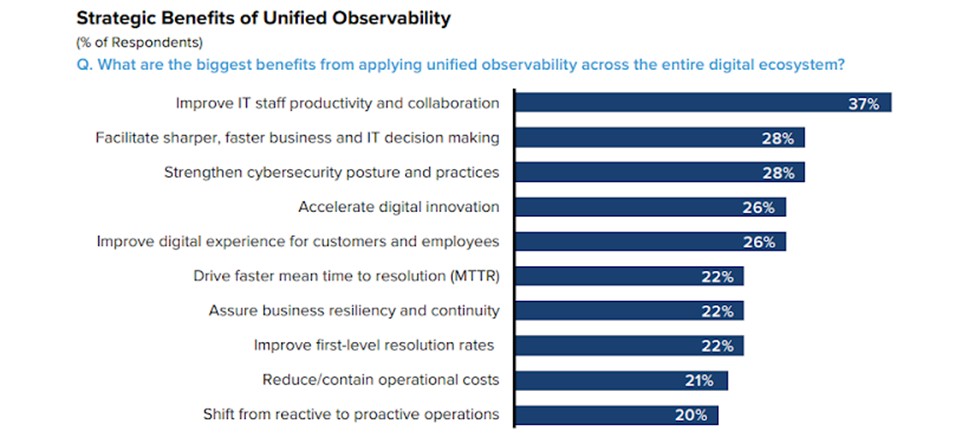
Yet, while broadcasters are steadily moving into all-IP workflows, adoption of observability in broadcast remains slow. Instead, critical network challenges often take a back seat to equipment selection, traditional monitoring, or simple content inspection.
It’s time for that to change. Observability and network intelligence bring measurable benefits to broadcast operations—from agility and cost savings to service quality and customer value
1. Improve Performance and Find Root Causes Faster
Networks are unpredictable, influenced by traffic patterns and routing decisions outside of any single organization’s control. That leaves countless possible points of failure.
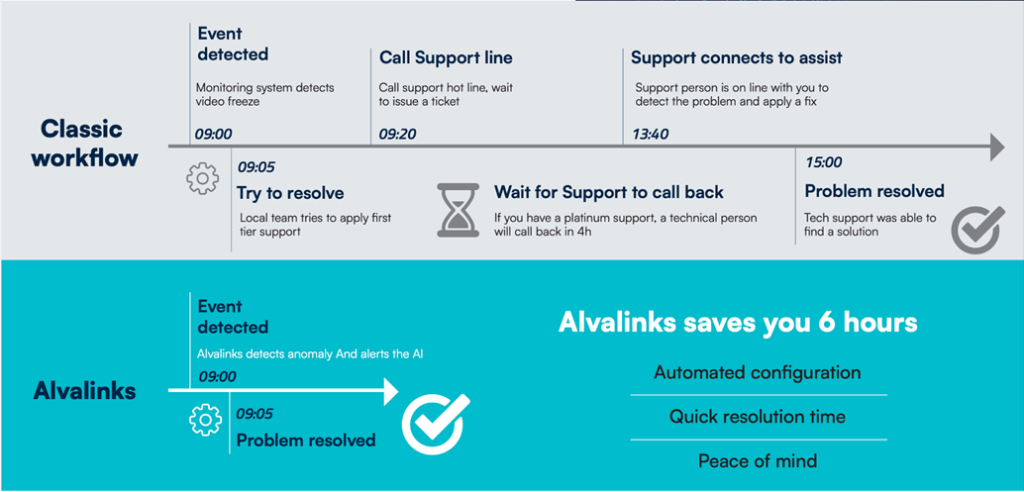
Traditionally, troubleshooting takes days, involving multiple teams and vendors just to isolate the source of a problem. With observability, engineers can trace and resolve root causes in minutes, drastically improving uptime.
When built into standard workflows, observability consolidates everything into a single pane of glass: alerts, notifications, comparison charts, and a live operational map. The result? Faster resolution, fewer outages, and stronger SLAs.
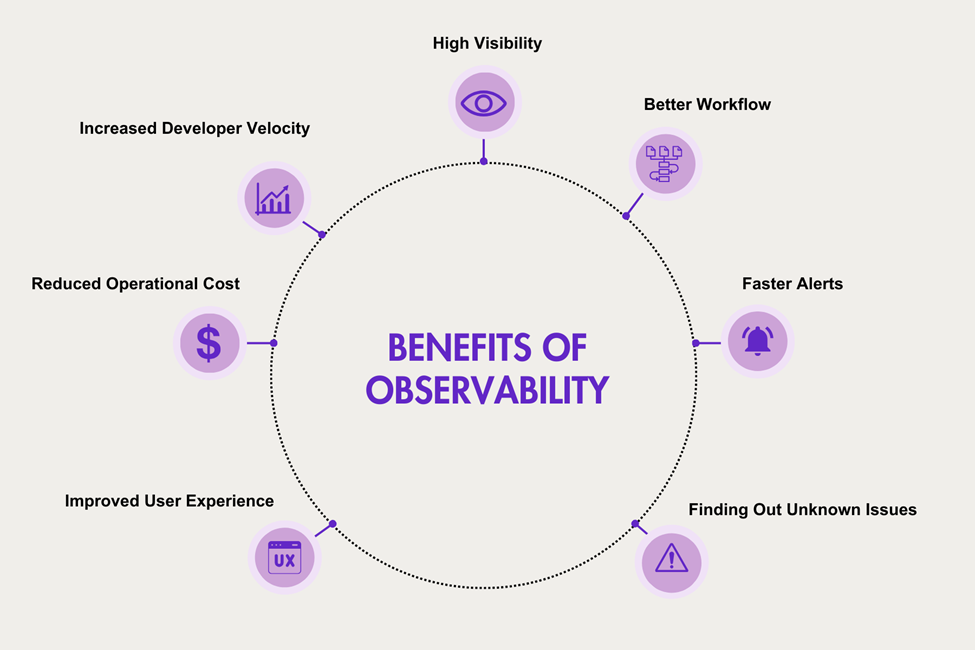
Reduce Operational Costs with Lower MTTR
Video delivery networks are prone to issues like packet loss, jitter, and latency. To protect end-users, many broadcasters rely on redundant multi-path networks (A + B). But every path must be monitored in real time.
Observability provides a 360° view of network health, combining metrics, logs, traces, and proactive testing. This helps operators spot issues instantly, trace their causes, and prevent long outages.
The payoff is significant: Splunk reports organizations that adopted observability cut MTTR by up to 95% and saved an average of $2M over three years.

3. Prevent Incidents Before They Escalate
Legacy monitoring tools only detect symptoms—compression errors, black frames, or frame freezes—at the output stage. By then, it’s often too late.
Observability brings the network into the equation, enabling operators to set intelligent alarms and receive real-time notifications at the first sign of trouble. Many issues can be corrected before they ever impact viewers.
According to Gartner, the average cost of IT downtime is $5,600 per minute. Organizations using observability have cut incidents by 50% and time-to-fix by 75%, saving millions annually.
4. Lower Travel Costs and Carbon Footprint
With the right tools, teams can validate network performance for a live event remotely, testing bitrates, jitter, and latency without sending engineers on-site.
This reduces both costs and environmental impact. For example, one Alvalinks customer saved $500K–$600K per season in travel and accommodations for a major sports league.
5. Deliver More Value to Customers
Network intelligence and observability not only streamline operations—they directly impact the customer experience.
- Faster issue resolution = smoother streaming experiences
- Better reliability = stronger brand trust
- Agile IP workflows = faster innovation and shorter time-to-value
According to PwC, 80% of customers value speed, convenience, and quality of service—and are willing to pay 16% more for premium experiences. Observability helps broadcasters deliver exactly that.
Observability as a Platform for Innovation
Innovation is critical, but in today’s environment, downtime or glitches are unacceptable. Observability gives broadcasters the confidence to roll out new features, adopt cloud-based workflows, and push the limits of IP—all without compromising performance.
By combining real-time visibility with AI-powered intelligence, observability creates a continuous improvement cycle: detecting anomalies, learning from them, and driving systems back above baseline.
The result? Stronger infrastructure, lower costs, and more engaging viewer experiences.
So the question is: What’s stopping you from adding observability to your workflow?